このページは編集途中です。
自作NAS(OpenMediaVault 6)にDockerを使ってStable DiffusionのWeb UI(AUTOMATIC1111)をインストールした時の覚え書きなどです。
なんかいろいろ試してたらインストールできただけなので、このページを参考にインストールする方は記述通りにしただけだとうまく行かないと思います。
自作NASのスペックは下記の通りです。
CPU:Celeron G6900 → Ryzen 5700x
MEM:32GB → 88GB (32+32+16+8)
GPU:RTX3060(12GB)
メインメモリはNASで他に動かすサービスにもよりますが、32GBクラスは必要ですね。(16GBでは足りなくなる)
編集履歴:
AUTOMATIC1111 v1.6.0対応へ書き換え
NvidiaドライバーとContainer Toolkitのインストール
Dockerを使ってStable Diffusion WebUIをインストール
拡張機能のインストールなど
拡張機能のインストール
拡張機能
設定
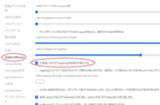
設定 → 元画像に合わせてimg2imgの結果を色補正するにチェックを入れます。
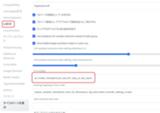

設定 → UI設定→ クイック設定に、sd_model_checkpoint,sd_vae,CLIP_stop_at_last_layersと入力します。
これを行うと、WebUI上で簡単にVAEとClip値を操作できます。
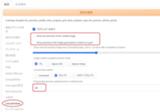
設定 → Live previews → Show live previews of the created image と、Show previews of all images generated in a batch as a gridのチェックをOFFにすると、生成途中の画像が表示されなくなるかわりにVRAMの節約と少しですが、画像の生成が高速になります。
(参考リンク:【検証】WebUI(1111版)のライブプレビュー(生成過程表示)による速度低下はどのくらいか?)
(個人的な設定として)Progressbar/preview update period, in millisecondsの値を100程度に?
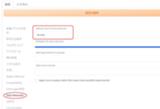
🎴を押したときにサムネイルが大きいので、設定 → Extra Networks → Default view for Extra Networks をthumbsに変更して設定を適用します。
設定 → ファイル名のパターン → の欄に、[seed]-[model_name]を追加。これで生成された画像のファイル名にシード値と使用した学習モデル名が追加されます。学習モデルデータの修復
アセットなど
自作NAS(OpenMediaVault 6)にDockerを使ってStable DiffusionのWeb UI(AUTOMATIC1111)をインストールした時の覚え書きなどです。
なんかいろいろ試してたらインストールできただけなので、このページを参考にインストールする方は記述通りにしただけだとうまく行かないと思います。
自作NASのスペックは下記の通りです。
CPU:
MEM:
GPU:RTX3060(12GB)
メインメモリはNASで他に動かすサービスにもよりますが、32GBクラスは必要ですね。(16GBでは足りなくなる)
編集履歴:
AUTOMATIC1111 v1.6.0対応へ書き換え
NvidiaドライバーとContainer Toolkitのインストール 
セキュアブートの無効化、Docker、Docker Composeはインストール済みとして進めます。
DockerでCUDAを使うにはホストにNvidiaドライバーをインストールしたうえで、Nvidia Container Toolkitのインストールが必要です。
ヘッダー ファイルを準備します。
/etc/apt/sources.listを開いてcontribおよびnon-freeを追加します。
具体的には下記のようにします。
リポジトリキャッシュを更新します。
nvidia-xconfigをインストール、実行します。
Network Repoをインストールします。
cuda-keyringパッケージをインストールします。
リポジトリキャッシュを更新します。
CUDA SDKをインストールします。
nvidia-docker2パッケージ (および依存関係)をインストールします。
Nvidia エンコード ライブラリと nvidia-smi をインストールします。
Nvidiaコンテナーランタイムをインストールします。
Nvidiaドライバーをインストールします。
エラーなく下記のDockerが動けば成功です。
なんかエラーが出たときは取り敢えず再起動&apt update && apt upgradeで行けるはず。
参考リンク:
DockerでCUDAを使うにはホストにNvidiaドライバーをインストールしたうえで、Nvidia Container Toolkitのインストールが必要です。
ヘッダー ファイルを準備します。
sudo apt-get install module-assistant
sudo m-a prepare
/etc/apt/sources.listを開いてcontribおよびnon-freeを追加します。
具体的には下記のようにします。
#/etc/apt/sources.list
deb http://deb.debian.org/debian bullseye main contrib non-free
deb-src http://deb.debian.org/debian bullseye main contrib non-free
deb http://deb.debian.org/debian-security/ bullseye-security main contrib non-free
deb-src http://deb.debian.org/debian-security/ bullseye-security main contrib non-free
deb http://deb.debian.org/debian bullseye-updates main contrib non-free
deb-src http://deb.debian.org/debian bullseye-updates main contrib non-free
リポジトリキャッシュを更新します。
sudo apt update
nvidia-xconfigをインストール、実行します。
sudo apt install nvidia-xconfig
sudo nvidia-xconfig
Network Repoをインストールします。
cuda-keyringパッケージをインストールします。
wget https://developer.download.nvidia.com/compute/cuda/repos/debian11/x86_64/cuda-keyring_1.0-1_all.deb
sudo dpkg -i cuda-keyring_1.0-1_all.deb
リポジトリキャッシュを更新します。
sudo apt-get update
CUDA SDKをインストールします。
sudo apt-get -y install cuda
nvidia-docker2パッケージ (および依存関係)をインストールします。
sudo apt-get update
sudo apt install nvidia-docker2
Nvidia エンコード ライブラリと nvidia-smi をインストールします。
sudo apt install libnvidia-encode1
sudo apt install nvidia-smi
Nvidiaコンテナーランタイムをインストールします。
sudo apt install nvidia-container-runtime
Nvidiaドライバーをインストールします。
sudo apt install nvidia-driver firmware-misc-nonfree
エラーなく下記のDockerが動けば成功です。
docker run --gpus all --rm nvidia/cuda nvidia-smi
なんかエラーが出たときは取り敢えず再起動&apt update && apt upgradeで行けるはず。
参考リンク:
Dockerを使ってStable Diffusion WebUIをインストール
先に、OMV上でCIFS共有ディレクトリを作成しておき、そこにgitをcloneします。
(学習モデルデータなどをPCからコピーなどするため)
上記を使わせてもらいます。
ファイルを取得します。
cloneしたディレクトリに移動します。
メモ:docker-compose.ymlの26行目に下記を記載
※スペースの数(インデントの位置)に注意(スペース4個)
初回にファイルの取得などを行います。
起動します。
ちなみに、アップデートする場合は下記のコマンドです。
下記のURLとポートでアクセスできます。
参考リンク:
(学習モデルデータなどをPCからコピーなどするため)
上記を使わせてもらいます。
ファイルを取得します。
git clone https://github.com/AbdBarho/stable-diffusion-webui-docker
cloneしたディレクトリに移動します。
cd stable-diffusion-webui-docker/
メモ:docker-compose.ymlの26行目に下記を記載
※スペースの数(インデントの位置)に注意(スペース4個)
nano docker-compose.yml
user: 1000:1000
初回にファイルの取得などを行います。
docker compose --profile download up --build
起動します。
docker compose --profile auto up --build
ちなみに、アップデートする場合は下記のコマンドです。
#gitからcloneしたディレクトリ(stable-diffusion-webui-docker/)に移動したうえで、
git pull
docker compose --profile auto build --no-cache
下記のURLとポートでアクセスできます。
http://(NASのIP):7860/
参考リンク:
拡張機能のインストールなど
拡張機能のインストール
拡張機能
この項目は完全に自分のメモです。
プロンプト入力を楽にする拡張機能
詳細はプロンプト入力を楽にする拡張機能を作りましたの回をご覧下さい。
WebUIの日本語訳拡張機能
生成する画像サイズや縦横比のプリセット機能を追加する拡張機能
画像を生成する際の設定をプリセットとして保存する事ができるようになる拡張機能
単純なテキストからプロンプトを作成する拡張機能
画像の背景を透過したり白背景にしたりマスク画像を出力する拡張機能
画像の切り抜き拡張機能 上記の拡張機能より、複雑な背景からも高精度に切り抜けるらしい
こちらからモデルデータをダウンロードして下記のディレクトリに保存しておく必要がある。
生成した画像をピクセル化する拡張機能
Dockerの場合、下記の場所にGitHubに記載されているpixelart_vgg19.pth、alias_net.pth、160_net_G_A.pthの3つのファイルを配置する必要があります。
https://github.com/aka7774/sd_images_browser
生成された画像を閲覧したりする拡張機能
どうもDocker上ではうまく動かない?
→https://github.com/AlUlkesh/stable-diffusion-webui...
モデルを管理、編集、作成するための多目的ツールキット
WebUIでControlNetを使えるようにする拡張機能
Dockerでは、下記の場所にhttps://huggingface.co/lllyasviel/ControlNet/tree/...からダウンロードしたモデルを配置する必要がある
Danbooruなどのタグをオートコンプリートできるようになる拡張機能
設定 → Tag Autocomplete → 表示されるタグ の数を10くらいにすると良いかも
更新停止 下記のフォーク版を使うように→ 更新が再開されたみたい
→https://github.com/zixaphir/Stable-Diffusion-Webui...
顔や手を自動で検出して修正をしてくれるStable Diffusionの拡張機能
Dockerの場合、下記の場所にモデルを配置する必要があります。
- Easy Prompt Selector
プロンプト入力を楽にする拡張機能
詳細はプロンプト入力を楽にする拡張機能を作りましたの回をご覧下さい。
- stable-diffusion-webui-localization-ja_JP
WebUIの日本語訳拡張機能
- Stable Diffusion WebUI Aspect Ratio selector
生成する画像サイズや縦横比のプリセット機能を追加する拡張機能
- Config-Presets
画像を生成する際の設定をプリセットとして保存する事ができるようになる拡張機能
- stable-diffusion-webui-text2prompt
単純なテキストからプロンプトを作成する拡張機能
- sd_katanuki
画像の背景を透過したり白背景にしたりマスク画像を出力する拡張機能
- PBRemTools
画像の切り抜き拡張機能 上記の拡張機能より、複雑な背景からも高精度に切り抜けるらしい
こちらからモデルデータをダウンロードして下記のディレクトリに保存しておく必要がある。
stable-diffusion-webui-docker\data\config\auto\extensions\PBRemTools\models
- Pixelization
生成した画像をピクセル化する拡張機能
Dockerの場合、下記の場所にGitHubに記載されているpixelart_vgg19.pth、alias_net.pth、160_net_G_A.pthの3つのファイルを配置する必要があります。
stable-diffusion-webui-docker\data\config\auto\extensions\stable-diffusion-webui-pixelization\checkpoints\
sd_images_browser
どうもDocker上ではうまく動かない?
→https://github.com/AlUlkesh/stable-diffusion-webui...
- stable-diffusion-webui-model-toolkit
モデルを管理、編集、作成するための多目的ツールキット
- sd-webui-controlnet
WebUIでControlNetを使えるようにする拡張機能
Dockerでは、下記の場所にhttps://huggingface.co/lllyasviel/ControlNet/tree/...からダウンロードしたモデルを配置する必要がある
stable-diffusion-webui-docker\data\config\auto\extensions\sd-webui-controlnet\models\
- a1111-sd-webui-tagcomplete
Danbooruなどのタグをオートコンプリートできるようになる拡張機能
設定 → Tag Autocomplete → 表示されるタグ の数を10くらいにすると良いかも
- sd-webui-lora-block-weight
- Stable-Diffusion-Webui-Civitai-Helper
更新停止 下記のフォーク版を使うように
→https://github.com/zixaphir/Stable-Diffusion-Webui...
- multidiffusion-upscaler-for-automatic1111
- adetailer
顔や手を自動で検出して修正をしてくれるStable Diffusionの拡張機能
Dockerの場合、下記の場所にモデルを配置する必要があります。
stable-diffusion-webui-docker\data\models\adetailer
設定
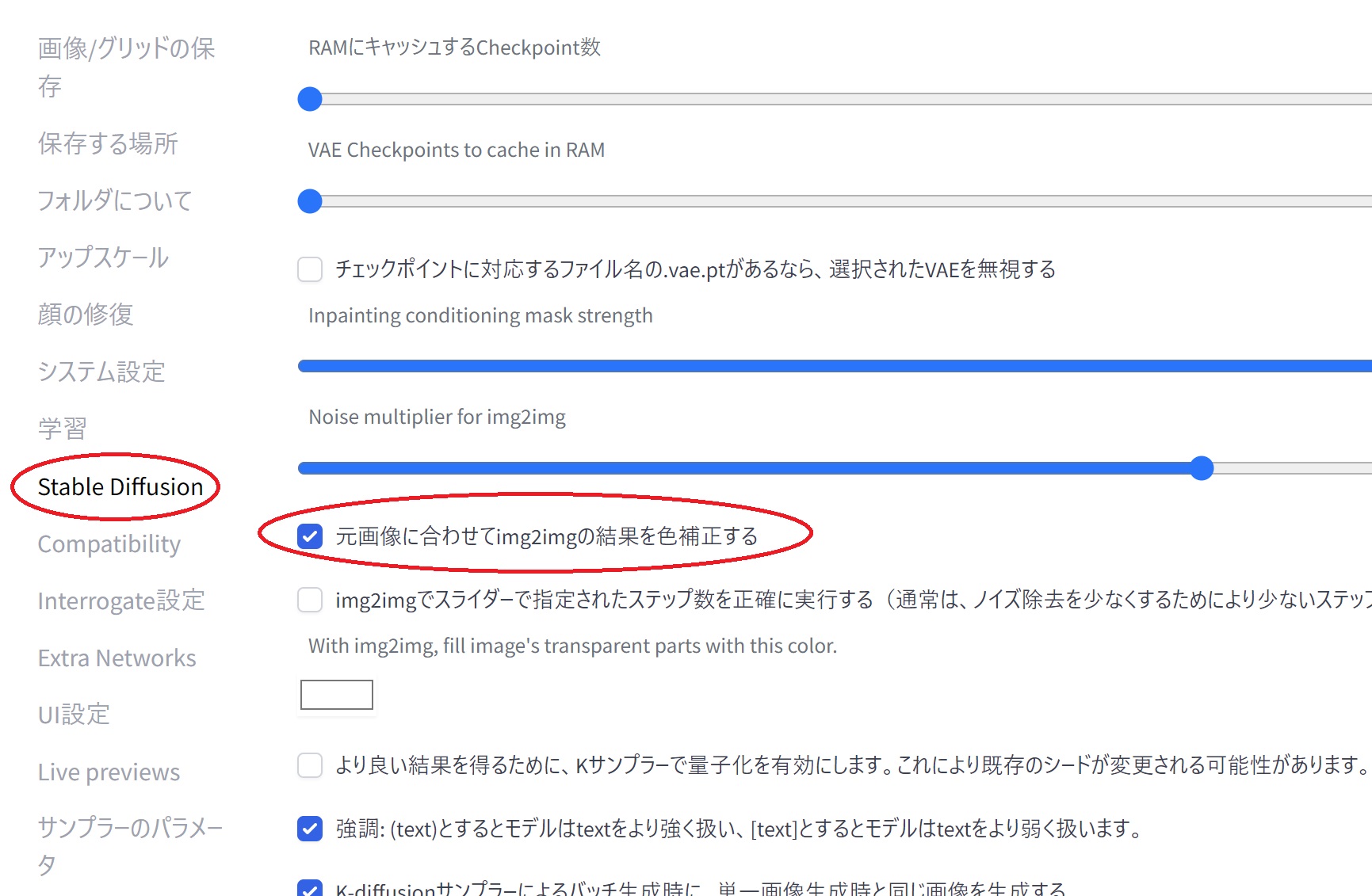
設定 → 元画像に合わせてimg2imgの結果を色補正するにチェックを入れます。
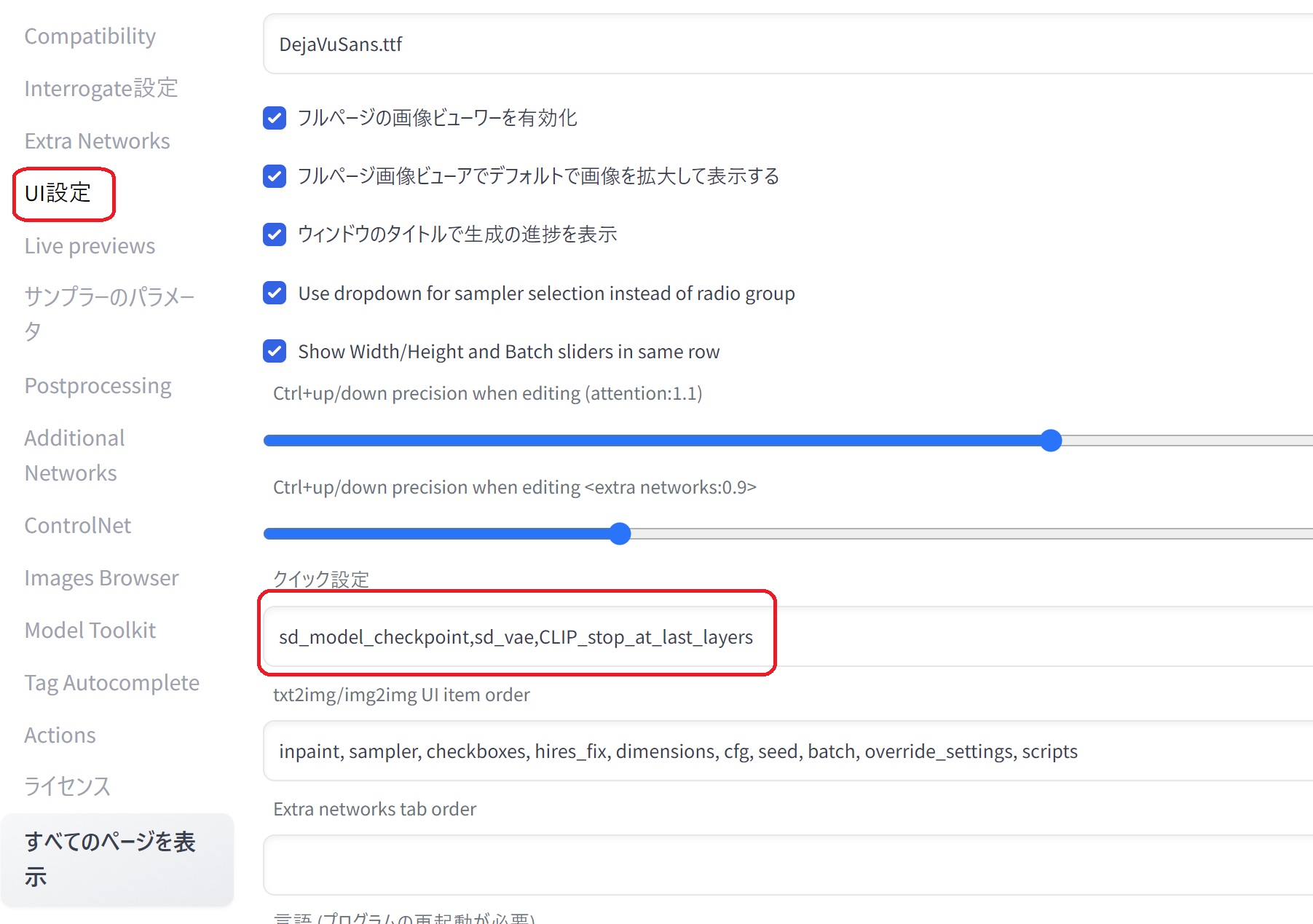

設定 → UI設定→ クイック設定に、sd_model_checkpoint,sd_vae,CLIP_stop_at_last_layersと入力します。
これを行うと、WebUI上で簡単にVAEとClip値を操作できます。
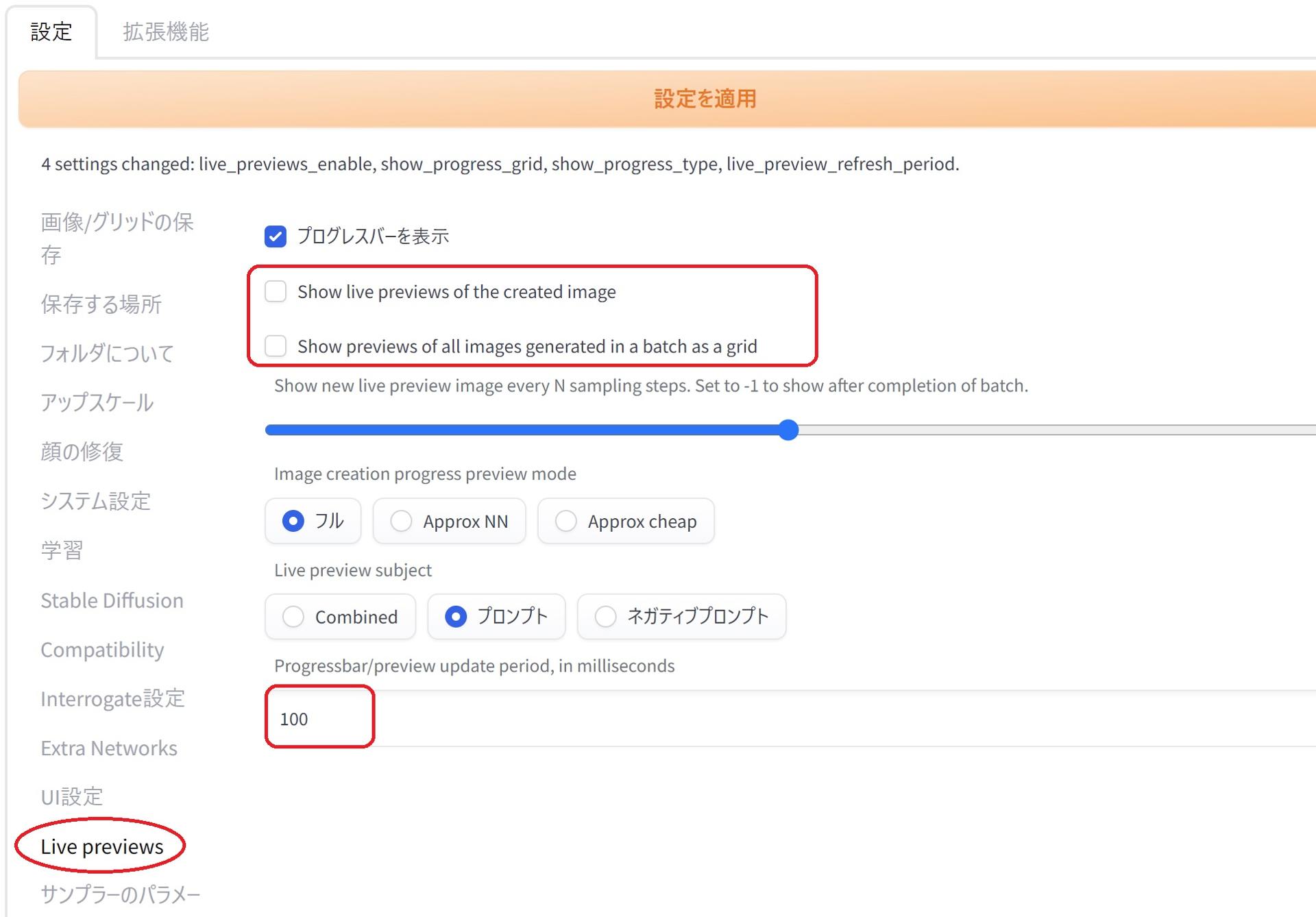
設定 → Live previews → Show live previews of the created image と、Show previews of all images generated in a batch as a gridのチェックをOFFにすると、生成途中の画像が表示されなくなるかわりにVRAMの節約と少しですが、画像の生成が高速になります。
(参考リンク:【検証】WebUI(1111版)のライブプレビュー(生成過程表示)による速度低下はどのくらいか?)
(個人的な設定として)Progressbar/preview update period, in millisecondsの値を100程度に?
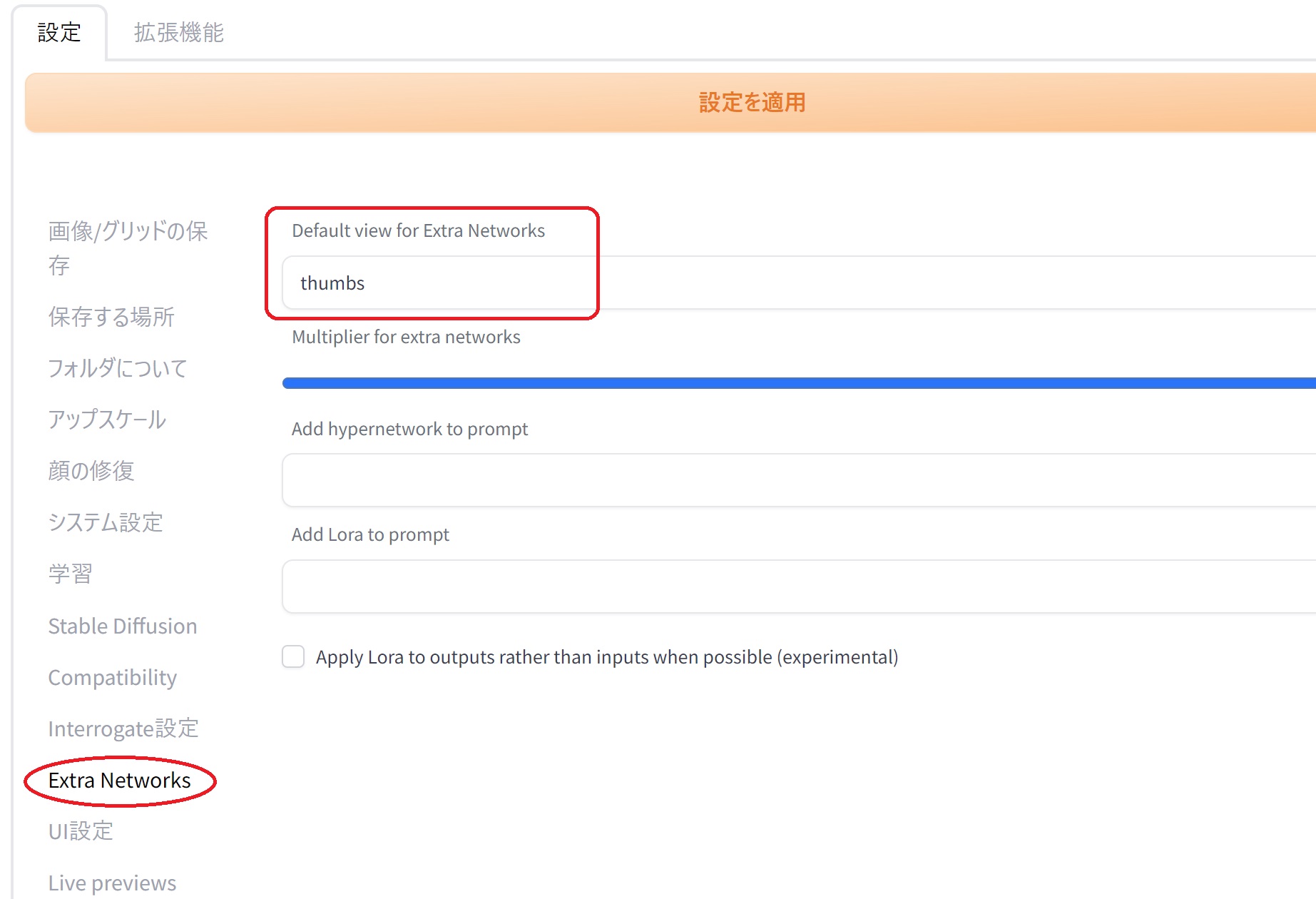
🎴を押したときにサムネイルが大きいので、設定 → Extra Networks → Default view for Extra Networks をthumbsに変更して設定を適用します。
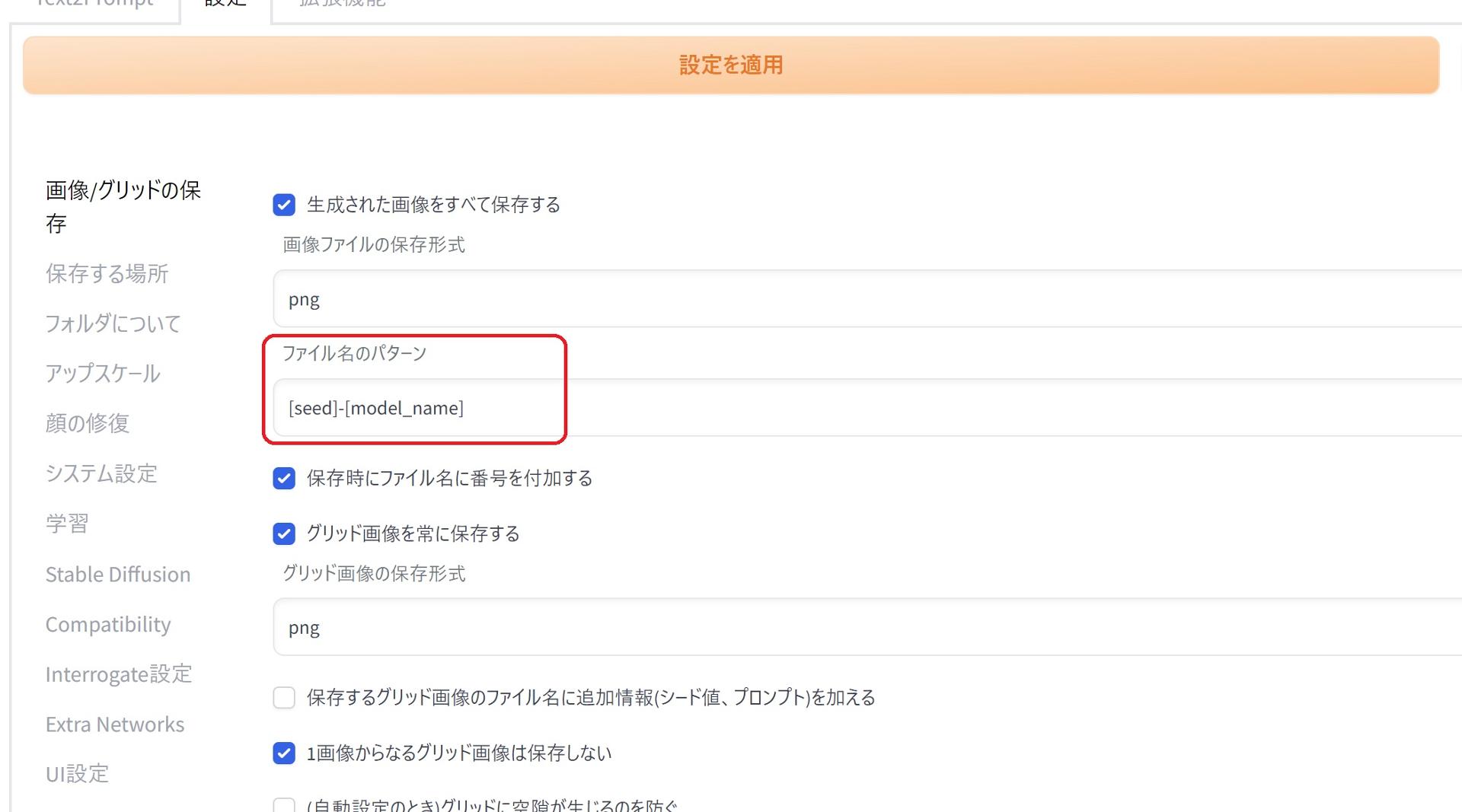
設定 → ファイル名のパターン → の欄に、[seed]-[model_name]を追加。これで生成された画像のファイル名にシード値と使用した学習モデル名が追加されます。
学習モデルデータの修復
2023年2月ごろ、配布されている一部の学習モデルデータが破損している事が明らかになりました。
破損した学習モデルを用いるとトークンが無視されたりするようです。(?)
拡張機能のstable-diffusion-webui-model-toolkitを使ってWebUIから学習モデルデータを修復してみます。
stable-diffusion-webui-model-toolkitをインストールしたら、設定 → Fix broken CLIP position IDsにチェックを入れて設定を適用し、CLIPの修復オプションを有効化します。

WebUIのToolKitを開き、入力にチェックしたい学習モデルデータを指定してLoadをクリックしてモデルをロードします。

名称から学習モデルの保存名を変更できます。
保存をクリックすることでモデルの修復や、ジャンクデータを削除してモデルを圧縮して保存できます。
また、stable-diffusion-webui-model-toolkitを使って.ckpt形式の学習モデルデータをセキュリティ的に良いとされる.safetensorsへ変換できるので、.ckpt形式のデータなら取り敢えずチェックしてみて良いかもしれません。
参考リンク:
破損した学習モデルを用いるとトークンが無視されたりするようです。(?)
拡張機能のstable-diffusion-webui-model-toolkitを使ってWebUIから学習モデルデータを修復してみます。
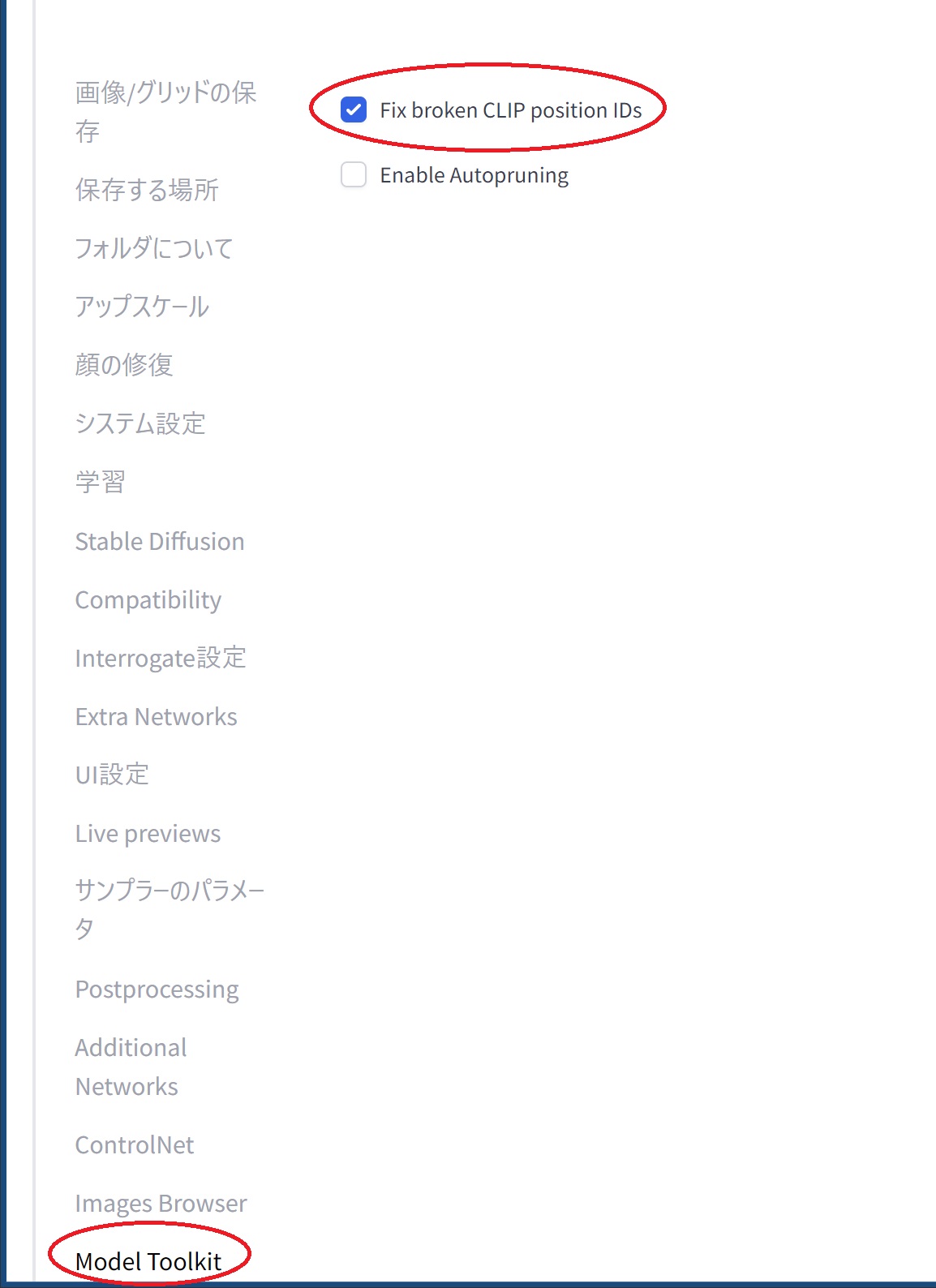
stable-diffusion-webui-model-toolkitをインストールしたら、設定 → Fix broken CLIP position IDsにチェックを入れて設定を適用し、CLIPの修復オプションを有効化します。
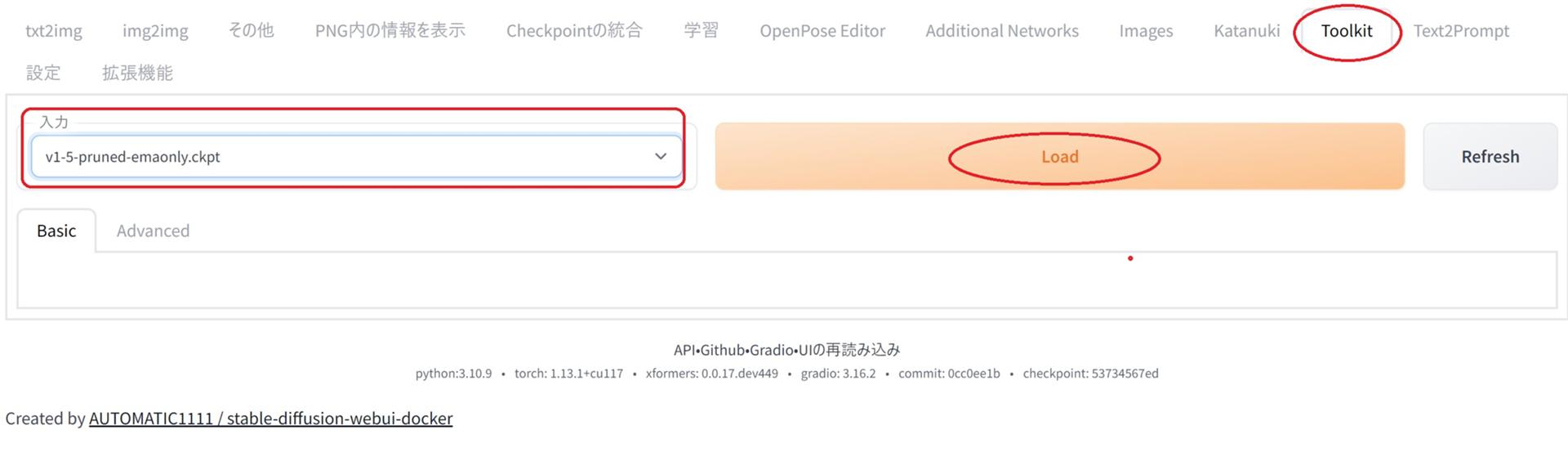
WebUIのToolKitを開き、入力にチェックしたい学習モデルデータを指定してLoadをクリックしてモデルをロードします。
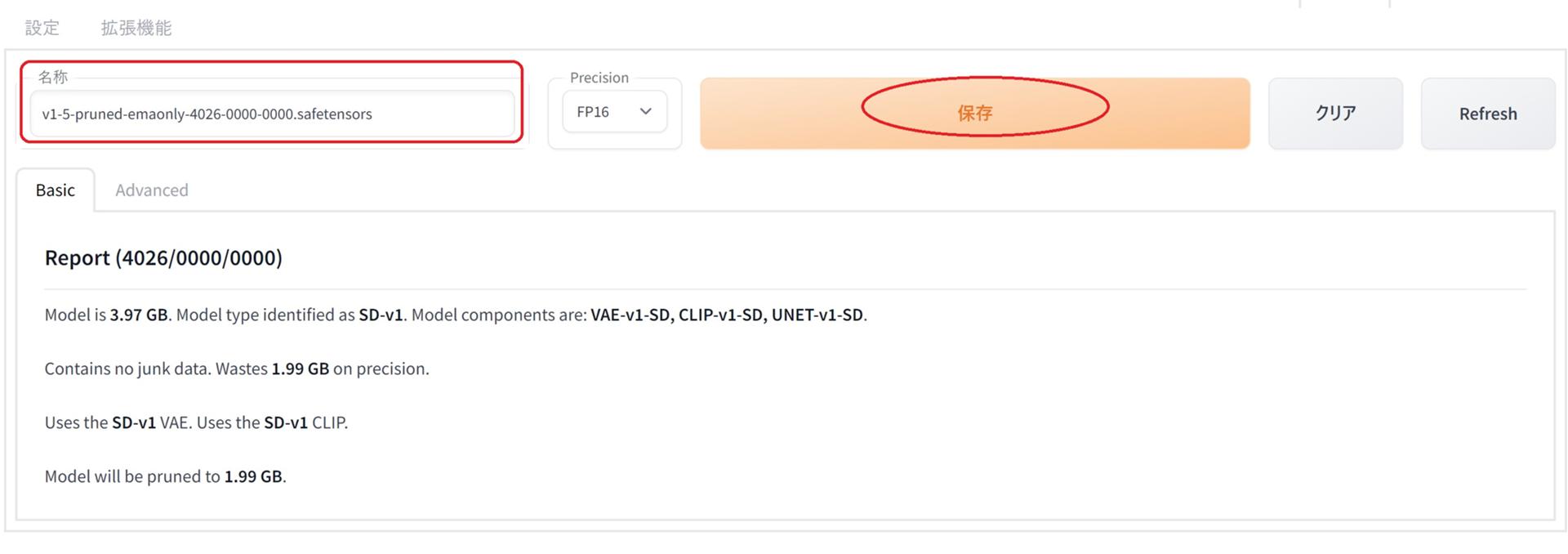
名称から学習モデルの保存名を変更できます。
保存をクリックすることでモデルの修復や、ジャンクデータを削除してモデルを圧縮して保存できます。
また、stable-diffusion-webui-model-toolkitを使って.ckpt形式の学習モデルデータをセキュリティ的に良いとされる.safetensorsへ変換できるので、.ckpt形式のデータなら取り敢えずチェックしてみて良いかもしれません。
参考リンク:
アセットなど
Blender(3.0以上)用のsd-webui-controlnet用の棒人形モデル
頻繁にアップデートされており、現在はVer4.5
BlenderでStable Diffusionを使用してレンダリングするアドオン
最近は更新されておらず、現時点ではあまり実用的ではない
MMDで深度マップとか法線マップなどを出力するMME
sd-webui-controlnet用の棒人形モデル(PMX)
頻繁にアップデートされており、現在はVer4.5
BlenderでStable Diffusionを使用してレンダリングするアドオン
MMDで深度マップとか法線マップなどを出力するMME
sd-webui-controlnet用の棒人形モデル(PMX)
タグ